
|
|||||||
Note: This essay was published in 2 parts in Keywords,
the jounal of the American
Society of Indexers (ASI). Part 1 appeared in Keywords
Volume 13, No. 2, April–June 2005. Part 2 appeared in Volume
13, No. 3, July–September 2005.
A common reaction from computer professionals, when told that back-of-book indexes are still written by human beings, is: "Don't they use computers to do that now?" The answer "No," must be followed by the explanation, the almost redundant "Because no one has been able to write a software program that can index books well." The key word here is "well." [Those indexers who like ripostes might ask computer programmers why humans are still needed to do computer programming].
What computers can do easily is generate a list of words or phrases in a work (book or manual) with the pages (or other locators or pointers) where the words or phrases appear, and arrange the list in alphabetical order. This gives the product some of the appearance of a professionally produced index. Such an index can be of some value to humans who need to find information in a book, but it is nowhere near as valuable as a professionally human-produced index.
If a book is in electronic format it may sometimes be easier for a user to use a search function than an index to find information. But to search well (efficiently and effectively) a user must have some of the same skills and knowledge of the book's topics as a professional book indexer. A good index is not just a list of words with pointers (locators, in publishing jargon). A good index is a structure optimized to help two human minds meet.
In addition to knowing the formal rules of indexing, professional indexers have developed a number of rules-of-thumb that help them to produce indexes that are highly valuable to book users. In addition, even mediocre human book indexers do certain activities, with definite results, with little conscious effort, that are exceptionally hard for a computer program to do at present. Human intelligence is clearly still superior to machine intelligence in the indexing game.
This paper will examine why quality indexing is such a difficult task for machine indexers (MIs). This process will illuminate aspects of the nature of the relationships between indexes, books, language, and real world knowledge. A number of paradigms will be considered for computer models of language, structuring data, and creating useful indexes (both back of the book and of more generalized sorts).
Useful indexes could be being used to solve a number of problems aside from rapidly looking up a subject in a book. They have applications in many aspects of real-world problem solving. In fact, the vocabulary of language is itself an index (of sorts). For humans (babies), learning about the world is an indexing process. Failing to index the world properly leads directly to failure to function well in the world. Adding indexing intelligence to machines would greatly enhance their ability to function in the world.
I will begin by examining several tasks routinely performed by human book indexers, pointing out along the way the difficulties involved and implications. That provides concrete examples to inform the discussion of the relationship between author, indexer, reader, language, and the world. This leads to considering the language acquisition process of children as an indexing process, and of indexing processes in general. After considering the relationships of indexes and maps, a requirements list for human-quality indexing by MIs (computer software & hardware) will be presented.
Let us begin by examing what seems to be a simple and easy to implement concept. One of the first concepts book index users learn is that of page ranges. For example
HTML, 203-207.
would indicate that the topic of HTML is taken up from beginning on page 203 and ending somewhere on page 207. Human indexers note page ranges almost automatically, perhaps occasionally thinking "does HTML end here, or perhaps at this other point?" Yet MIs can't accomplish this simple task without humans prepping the text for them. Why? Because to a machine indexer HTML is a string of characters. How far after the string HTML appears is the author still discussing HTML?
As someone who is a computer programmer as well as an indexer, I could make some rules for MIs to try to fake a knowledge of page ranges. A simple one would be:
If the string "HTML" appears, find its last appearance and mark the end of the page range at the end of the paragraph in which the last "HTML" appears.
If, however, the author writes substantially about HTML for 5 pages, talking about hypertext links and tags, there may only be one appearance of the string "HTML." A computer algorithm that was prepped with a list of words related to HTML might look for the last occurrence of the set of words in the list. But words are ambiguous. For instance "tag" does not necessarily mean "HTML tag." So the list of related words may contain words that give false results because they are also used in contexts other than related to the subject.
"The index has an error. The author stopped writing about HTML at page 205." Human's could argue about such a statement, but what of machine indexers? When the humans are finished arguing, will there be a rule that lets the MI know when the next passage about HTML ends? Will the rule be easily transferable to passages about HTTP? To passages about RNA, or about vaguer concepts like "immune system?" Will RNA-based virus boundary rules work for texts about computer viruses written in C++?
Hand writing a computer program that will do a good job indexing a particular book is currently more expensive than paying a professional indexer for the service.
Another problem with page ranges is that they can be subdivided. Unlike the subdivision algorithms required for fractal generation or most forms of analysis, it takes real, that is human, intelligence to appropriately subdivide an index entry with its page range. Some use guidelines of the sort "if the page locators cover 6 or more pages, break down into sub-entries." A more difficult question is whether to break a page range into two or more entries at the same level, or to keep as one entry at that level with subentries at the next level. The only general answer (if the goal is a good, useful index) is that the indexer (machine or human) must understand the subject matter, the author's intent, and the needs of the index users in order to make such a decision in a specific case.
Some indexers create page references for all mentions, or substantial mentions, of a topic. There are some types of books where this may be appropriate. But have you ever looked in an index and spent time finding page after page, getting no useful information that was not in an earlier reference to the topic because the same information is simply repeated at each point? Often this is an indicator of poor writing or thinking by the author, but certainly it is not the indexer's job to torture users by compounding the error.
The current run of software that produces indexes is particularly bad at this, since a topic may be mentioned dozens or even hundreds of times in a book. A professional indexer wanting to keep so many entries on a topic would break them down into second level entries. This is something software cannot do using a simple algorithm. Only understanding the relationships of subentries to entries, including the meanings of words, would allow this to be accomplished.
Given the use of modern word processors by authors, repetition is sometimes word-for-word. In that case a computer indexing program would be able to recognize repetition. If the repetition is not word-for-word, a program that does not understand the actual meanings of words will not spot the repetition.
Conversely, sometimes a passage that is in some sense repetitious is still important to index. An example might be a warning about potential software errors. The wording might be the same, but it may be important to the reader to be able to find all the cases that may generate an error. Only a knowledgeable indexer with a sense of "importance" can correctly make case-by-case decisions about whether an entry is likely to be useful instead of noisy.
There are many problems analogous to page-range determination (requiring the drawing of boundaries) in the human language domain. Almost every ordinary word in the English language carries with it the question of coverage. No adult adept at English would dispute that the following sentence can be used to accurately describe a situation:
"That is not a cat; that's a lion!"
And yet few would dispute the following assertion:
"A lion is a cat."
Simplistic logic is not much help here. Some would argue that more precise use of the English language would help: "That's not a house cat!" Any particular difficulty might be overcome in this way, but it is humans as a group who sort out such uses of language. If just a few nouns were lacking a tight definition, we might be tempted by the project. Even in science and technology precise, clearly limited subjects are in short supply. Make a definition of most things in the world, and a set of questions can be easily generated (by humans) that point out the tendency of the real world to blur. "Light Emitting Diode." Well, what if it emits infrared radiation? What if it is faulty? What if something appears to me to be a LED on an instrument panel, but it's light isn't produced by a diode?
This problem is remarkably similar to (and in practical indexing connected to) the page range problem. If a text switches from discussing a laser to discussing a maser, do I terminate the laser locator and create a separate entry for maser? Is light a general term for electromagnetic radiation (as in: the speed of light), or is it specific to the frequencies visible to the human eye? If there are 3 pages total on the topic of amplification by stimulated emission of radiation, and the laser/maser divide appears to be accidental rather than fundamental, an indexer should take a different approach than if there are 5 pages on lasers and 23 on masers. [I might create an entry such as:
lasers, 23-27. See also masers]
Verbs as well as nouns have their boundary issues. Concepts expressed in phrases, sentences, and whole books have boundary issues. While it is true that there are mathematical models for probability, overlaps, and topologies which have been applied with great success to problems such as quantum physics, so far they have not been successfully applied to clarifying the meanings of human languages for MIs.
Two-level book indexes are typically easier and faster for most users than indexes with a single level or more than two levels. But no matter how many levels an index has, it is likely have to deal with hierarchies of concepts that have more levels. Which is one reason two-level indexes have become the standard in computer software texts.
How should a professional indexer (or MI) deal with a greater than N + 1 level hierarchy of terms in an N level index? This happens all the time in computer software books now that hierarchical objects are the basis of most programming.
Suppose one has a set of terms requiring indexing related hierarchically as TopObject, Mid1Object, Mid2Object, LowObject. This happens frequently in computer texts about object libraries.
In order to make sure the reader can always find any of these terms on the first try you need permutations of all terms as first-level entries, and within each first level entry permutation of all lower level entries. In some cases it might even make sense to have a higher-order object as a subentry to a lower-order object, but I'll ignore such cases. So the index of the hierarchy would appear as:
TopObject
-----Mid1Object
-----Mid2Object
-----LowObject
Mid1Object
-----Mid2Object
-----LowObject
Mid2Object
-----LowObject
LowObject
That arrangement can certainly be created with a computer algorithm. Consider that in most real cases there are multiple terms at each level. Suppose there are just 2 second-level terms, Mid1Object1 and Mid1Object2, and each of them has 2 third level terms, and all third level terms group 10 fourth level terms. To completely cover them in the manner shown above would require 170 entries. Book publishers generally will not allow a long enough space for the index to offer such complete coverage. Indexers must make choices. This is especially true because TopObject, in fact all objects, probably have substantive subtopics in addition to their contained objects (in computer programming texts, for instance TopObject might have topics such as initialization, parameters, properties, or its purpose or definition).
A method often used to offer the appearance of complete coverage is to use See references:
TopObject
-----Mid1Object. See Mid1Object
Mid1Object
-----Mid2Object. See Mid2Object
Mid2Object
-----LowObject. See LowObject
LowObject
Again, an algorithm could generate this. It is much more compact than a full coverage. The problem is it expects too much of the user. First, the user often has to do two lookups instead of one. In addition, users often don't know the terms they need to look up. For instance, a reader does not know the name of the LowObject, but only of the Mid1Object. The reader then has to find Mid2Object to find the name LowObject.
Good human indexers can produce an index of any reasonable length that minimizes user lookup time and maximizes user success rates. The result, for our example, is almost always somewhere between the complete coverage and absolute minimal coverage.
Human indexers can do that because they work with three maps in their heads: the map of the book or text being indexed, the map of the subject area, and the map of the knowledge levels and mental habits of likely users. A good indexer will know in great detail when to use full coverage and when to be selective. Could a computer program and database accomplish the same? None do yet. When creating an index of a book that has subject hierarchy issues, a human indexer will rely heavily on the concept of "importance".
The main point of book indexing is to speed up human retrieval of meaningful information. For that reason over-indexing, which may lead to multiple fruitless searches, is not a good solution. At the same time printing a complete (in terms of coverage) index is usually prohibited by cost considerations.
So one consideration professionals give considerable thought to while indexing a work is deciding which topics do require entries, and which do not. Indexers of books who do not understand the subject matter may take a machine-like approach to this task. Their rule might be if it is a noun, index it. If their publisher is not interested in providing the reader of the book with an index that is a quarter as long as the book itself, despite being in 6 point type, the indexer will be asked to shorten the index, which is to say, guess at which entries are important.
As usual, professional indexers have provided some rules of thumb for this. The most basic is: the more the author writes about a subject, the more important it is. A topic with an entire chapter devoted to it is more important than a topic that has a couple of pages devoted to it, which in turn is more important than topic covering a single paragraph or sentence. At the bottom of the priority list is topics the are merely mentioned.
We can imagine, if the page-range problem can be solved, that an MI could use the above general rule to measure the importance of a term becoming an index entry. Given the allowed length of the printed index, the terms with least importance could be eliminated with great precision.
But we know that a single sentence, say a key definition, may be more important than covering longer lengths of text that add little to the discussion. So, given a goal of helping a human user, the indexer's knowledge base and judgement are going to do far better at sorting terms in order of importance than any algorithm based on text length.
In fact human indexers make judgements as to importance as they read the text; they are often able to draft an extremely usable index approximating a required length (say 5% of the overall text length) on a single pass.
Professional indexers have many rules and guidelines for constructing indexes, some of which I have identified above. Naturally some indexers are more rule-oriented than others. Whenever there are a set of rules that are to be obeyed in a complex terrain, at times one or more rules will conflict with each other.
I believe the overriding rule, when creating book indexes, is to help the user. This may seem like a very vague rule, but all human index writers are also index users. Hopefully they use indexes of books on the same fields as the books that they index. Indexers can keep in mind that any given book has a spectrum of users. A technical book that is aimed at professional computer programmers, for instance, may also be referred to by student, academic, or hobby programmers. A professional programmer might look up a function by its known name, where as a student may be looking for a function that fulfills a role. Both options for look-up should be present for important functions.
Importance is the main criteria for helping the user. But there is no doubt that users sometimes look up trivia. If the length of the index allows for it, certainly trivia can be indexed. But to index trivia rather than deeply indexing important subjects is a mistake.
Machine generated indexes, in their present state, are more helpful to users than having no index at all. Amateur created indexes (usually by the author of the book) are usually at least as useful as machine-generated ones. If the amateur knows the subject materials but not professional indexing style rules, their mistakes tend to be largely stylistic. If a professional indexer does not understand the material being indexed, the indexing errors tend to concern the choices of entries. Professionally produced indexes are usually far better than machine-generated or amateur-created indexes. "Better" here means that users can find the information they seek with minimal effort.
Non-fiction book authors are consciously trying to convey a body of knowledge to the readers of their books. The author and indexer each enter the enterprise with a body of knowledge. Their knowledge bases may or may not be very similar. At minimum both the author and indexer are proficient in the language used for the book. We might expect, therefor, that a machine indexer must be proficient in the language to do a good job of indexing. The author has a body of knowledge which he distills [note MI's: example of metaphorical use of "distill"] into book form.
The indexer also has a body of knowledge. Reading the book (which would be impossible without a pre-existing body of knowledge) the indexer, like other readers, learns what the author conveys. It may be a particular arrangement of knowledge the indexer already has, but typically the indexer does some, perhaps a lot, of learning while indexing. The index reflects both the knowledge of the author and of the indexer. The author does not have to know how to create an index as he writes the book.
Both the author and the indexer have a knowledge of the knowledge likely to be present already in the book's target readers (and index users). These readers might fall into classes: students with no prior knowledge for whom the book is course work; workers in the field who use it only for reference; etc., depending on the book.
If the author has written an introductory text aimed at initially ignorant readers, it is possible that the indexer may do a good job without knowing much subject matter. If the author has written a more advanced text, an indexer with no knowledge of the subject matter is likely to produce a poor (not that helpful to users) index. Often the indexer will have a good general knowledge of a subject such as computer science, and will be indexing a book on a relatively narrow subject (say C++ programming, or graphics algorithms). Given that poor indexes are produced by human indexers who do not understand the subject matter, we might expect that an MI will produce a poor index if it does not understand the subject matter. "Understand" is, admittedly, a difficult to define precisely. We can also say the MI needs to begin with a knowledge base similar to a human indexers, and needs to be able to learn (add to its knowledge) just as a human indexer does.
A professional indexer who indexes a book on a subject that is similar to a prior book they indexed will have a general index framework in mind. Such an indexer might think thoughts such as "ahah, my first entry on the subject of Internet browsers," or "oh no, she's writing about event delegates, I've had trouble understanding that in the past."
Knowledge itself is indexed (somehow) within the human mind. The indexer reads the word "laser" and calls up what the indexer knows about lasers, which helps in the interpretation of the text. Unlike back of the book indexes, the human mind's index is not alphabetical. One has no sense of thinking "laser, that is an l word, after lap and before lattice." The best current theory is that language access in the human brain is nearly holographic and that this is possible due to the nature of neural networks.
Since back-of-book indexes solve some difficult (for machines) real-world language problems, it should not be a surprise that indexing paradigms can be useful in solving language problems other than creating indexes themselves. In this section general questions of the relationship of indexes to language will be considered.
Internet search mechanisms as indexing
Internet search engines typically produce temporary index-like search results to World Wide Web content. One mechanism for generating and sorting such temporary indexes, reputedly used by Google, involves counting the number of links into a particular Web page. This allows an algorithm to measure how many Web page creators thought a particular page, usually about a particular subject, was important enough to point to. Thus the assigning of importance problem discussed above is solved by surveying the aggregate assigning of importance by the humans involved in constructing the data pages of the Web.
A book and its index could be placed on the Web (or similar system) and then trial users tracked to see what subject matter they were seeking and how effective the index was in helping them. Using the results of what people actually found or failed to find using the index, it would be possible to construct an index of the book based solely on reader usages. Unused entries could be eliminated, allowing for a compact printed version of the index. An index compiled in such a way should save future users time while allowing the print version of the index to be relatively compact. Such an index would in effect contain the weighted knowledge base correlations of all the readers in the sample.
While an index for a book could be constructed this way, the economics are currently prohibitive. No book publisher is likely to undertake the development costs of such a system.
Language as an index
In the mind/brain of each person who knows a language such as English, the vocabulary of the language serves as an index to the known world (but not the only index).
For each individual person the known world is primarily in past time and represented as memories. Included in those memories is a vocabulary and a grammar that are intertwined with other memories. A person who has not seen an elephant in person may remember that "elephant" is a large land animal with certain characteristics because that person read it in a book or saw it on TV or heard it from another person. The word "elephant" serves as an index, or pointer, to what the person knows about a certain animal. Any given word such as elephant may be connected to a variety of memories. In some cases language fits the entry/subentry model of book indexes very well, for instance "cat" being a general category, but if questioned someone might say, "but there are other cats besides the house cat, for instance lions and tigers."
What makes human knowledge and English (or another human language) as an index different from machine database type knowledge is the rich set of associations. Locators point to memories, which may be words (e.g., if one first read the word elephant in an unillustrated book) or directly from the senses. There is no division into levels of entries; to try to make a hierarchy, one would have to have thousands of interlocking levels. Several words may have locators pointing to the same memory: "tiger," "danger," and "striped" might point to the same memory, for instance. Phrases like "my birthday" or "my alma matter" could point to large numbers of memories.
Good readers instantly (on human time scales) recognize every word in their vocabulary while reading. Quite complex pieces of knowledge, whether from a novel or a text book, can be integrated into the prior knowledge base as fast as the reading goes. Critical readers may spot internal contradictions or instances where the text contradicts their prior knowledge. The auto-indexing capabilities of the human brain is likely the key to these abilities.
Language Acquisition as Indexing
In the brief discussion of language as an index, we see that words are acquired with associations. It would be interesting to know on what framework the brain hangs words and associations other than general purpose biological explanations like "neural networks."
Since the memory-language area of the brain seems to work on an association basis, do we add anything useful (or insightful) to our picture by saying that the brain is indexing as it acquires language and other memories or knowledge? If nothing else, it frees us from a pure neural network model for programming these abilities. If a computer system uses a different method of operation, but achieves the same result, then we should be able to build machine knowledge bases that can achieve many or all of the desirable traits MIs and other machines lack at present.
In the individual human knowledge base (brain), indexing terms and locators are in a constant state of modification. The external sensory world provides constant feedback on the quality (usefulness) of the index. Fail to index foods properly and the result can be poisoning or starvation. Fail to index predators properly and the result is death. In our slightly less dangerous modern society people are often rewarded according to their ability to recall appropriate information associations.
Suppose then that we are convinced that machines need human-like knowledge bases in order to do tasks requiring real language skills. We set out to build a machine that automatically indexes its experiences of the world, using a language system like English. It is an obvious question to ask: well, what happens as a human baby does it?
Having read various neuro-linguistics theorists' theories, and having done some actual watching of babies learning, what makes sense in terms of our indexing paradigm (and being thankful that grammar acquisition itself is not part of this project)? Babies start having sensory experiences, including hearing language spoken, long before they begin articulating words or showing (by their reactions) that they understand words. At some point they learn their first word, for instance "mama," which serves as an index entry. Other words follow gradually and then quickly, including abstract words like "no." Things in the sensory world take on names, and changes are correlated with verbs. So we can assume humans have functions that are able to correlate sounds (words) with various events in the world. Thus words are indexes to meaningful knowledge about the world.
We must also assume functions that are able to place words and objects into the schemes we call maps and pictures of the world.
Model for Word Meaning Acquisition
Suppose we try to construct an indexing system correlating to the word-meaning acquisition system of humans.
Let the most basic construct in the model be the "word-object." This could be connected to memories of all sorts, raw and analyzed, including other word-objects. Memories would also be held in objects, and the connections themselves would be objects. In addition we will need map objects and some functions (to be specified as needed).
When a word is learned certain essential characteristics, memories or subsets of memories are connected to it; other connections can be added over time.
A simple, common word like "dog" would be richly
connected. Figure 1 shows some of its connections. There are connections
to other words, to memories, and to relationships like "kind
of." Secondary connections may be important to understanding
certain aspects of dogs. Internal to the word-object should be
the most essential characteristics.
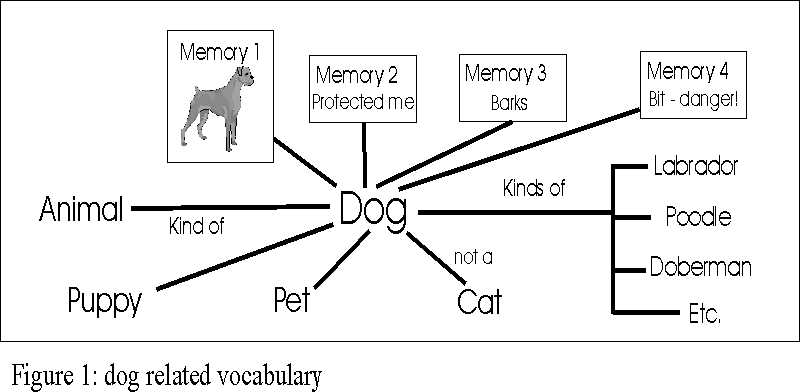
Given the model, the acquisition process is straightforward given a few functions. The main function is able to associate a word (sound and written word) with a set of memories. Various abstraction functions are needed.
The access process is also straightforward, if we can assume a function that approximates holographic access to words.
The Indexed Ordinary Geographic Map
Ordinary geographic maps (2 dimensional maps of terrain) give a picture of the world that is typically much simpler than a book about a topic. To make such maps more useful they often are indexed, with the locators being from a coordinate system, usually a numbered dimension and a lettered dimension (or for more precision, latitude and longitude). Most people have experienced the utility of maps (paper street maps, for instance) and the indexes that come with them. Maps can represent other constructs besides geography. In computer science we speak of memory maps, for instance.
Books as Maps with Indexes of "Places"
Consider someone hunting a treasure. As an example we'll use a new employee who claimed to be fully versed in creating Adobe pdf files, but who actually has many gaps in her knowledge. She needs to find answers to her questions quickly, and is using a book "Everything You Need to Know About Acrobat" to find the answers. In effect the page numbering of the book corresponds to the coordinate grid and the entries in the index correspond to places on a map. A poor index could cause a our hypothetical employee to lose her job.
One major difference between word indexes and maps is that cities (or other place named in maps) are well-defined and subjects suitable for entries are not always so well defined. The book is a sort of map of an area of knowledge, but the author has far more flexibility in presentation schemes for his knowledge than a map maker does. Hence the book and its index is both potentially more useful, and is more difficult to construct.
Maps as Indexes
Consider a map that has a coordinate grid and a list of cities in alphabetical order along with their positions on the grid, that is, an index of the map. Such an index could be considered to be a meta-index in the sense that the map itself is a kind of index to the geographical, sensory world. A geographical map is most like an index in that its chief function is to provide people with locators; instead of finding a subject in a book, one finds a place on a map (and thereby has an idea of how to go there). A map that is not itself indexed can be used in a manner similar to an index.
A geographical map is least like a book index in that it shows visible relationships between places. Book indexes have only one kind of visible relationship: between varying levels of entries. Because of the alphabetization system typically used, two adjoining indexing entries can have a maximal conceptual distance from one another.
In the same sense any book index is a meta-index (because the book itself is a sort of index). But a book is so different from an alphabetical-list-with-locators index that using language in this way confuses rather than clarifies.
Indexes as maps
The index can be thought of as a map to the book, just as the book is a map of the area of knowledge X. An index can be a good map or not, depending on the skill of the indexer. There is, however, no framework like the Euclidean view typically used in a map. An index is not a very good picture of a book. One can learn about a book by scanning an index, but that is not its typical use. It is used for rapid access to information. The framework it is hung on, alphabetization, allows humans to rapidly find an entry, but provides no other information about the relationships between topics.
Indexing After Mapping
Likely most maps are indexed after they are completed. The map is given to an indexer (perhaps even a machine indexer) who looks in each grid of the map and creates entries, with the grid coordinates as locators. Then the entries are alphabetized or otherwise grouped for the convenience of the users. Indexes of maps tend to be thorough and completeness is both easy to assure and desirable. We assume all streets or cities are important, or they would not be on the map.
Book indexes are also created after the books are written (or sometimes after a chapter is written). Each page, like each grid of the map, is examined. However, book indexes are often about relationships, and synonyms can be a a problem. Book indexers may rearrange a scheme as they progress through a book. Most commonly a top-level entry may grow too large, requiring it to be broken into subentries. Or a subentry grows too large, requiring it to be transformed into a top-level entry.
Indexing While Mapping
Indexing a map as it is created is conceptually easy as well. In fact, the index might be created first, and the map could be created from the image. For instance, surveyors might cover an area they wish to map by finding hilltops. Each top could be entered in a list with its elevation, latitude, and longitude. Some system would ensure the entire area to be mapped is covered. Then the map is drawn using the list, which is also the index to the map.
An author could use a mark-up system to create index entries as the book is written. Such mark-up systems are available in or for most publishing software packages. Depending on the skill of the author, this may or may not produce a good, usable index. But there is no reason to think that an MI, at present, could index (with mark-up tags) as an author writes, than to think a machine could write the book in the first place.
Moving Animals and Complex Locators
Maps of the paper sort showing geography don't usually show animals
on them, though they could. Animals move. Hunters (human and probably
wolves and other highly intelligent predators, and perhaps some
herbivores as well) include their knowledge of the animals they
hunt in their mental maps.
Human language can be dissected into words that identify things (including abstract things, such as actions, using verbs) and the relationships between things. Maps that keep track of numerous types of things that move around and otherwise change their relationships require a fluidity that paper is limited in displaying. The human mind is highly adapted to this type of mapping. Humans can talk about their world with little effort. That talk can be written down.
Indexing Books: Complex Targets with Simple Locators
Many of the roadblocks to using machines (MIs) to produce high-quality book indexes correspond to information structures analogous to some of our mapping examples.
Knowing that elk wander around certain hills in summer and certain valleys in winter might be indicated by oral communication or in a hunting guidebook, hunting and gathering being basic human abilities. The book might be indexed for elk locations with
elk
-----Summer locations, 37
-----Winter locations, 38
This is not so different than indexing a technology book to help a programmer find the section for TCP/IP sockets for a particular language:
sockets
-----C++ library classes, 97
-----Java library classes, 103
Now suppose a book has a short section on Java library socket classes in which a function LoadBufferX is mentioned. In a later section of the book say page 132, without reminding the reader that LoadBufferX is a Java socket class, the function is again discussed. A good indexer (human or MI) include this island of information as a subentry under sockets:
sockets
-----C++ library classes, 97
-----Java library classes, 103
-----LoadBufferX, 103, 132
This is not unlike a map of elk locations in winter, which would be remiss if it did not show a pocket of elk that regularly overwintered in an area separated from the main range.
For humans, this mapping/indexing process is intuitive because it is an integrated survival skill. For MIs a system must be created that correlates to it.
Based on the above discussions, a machine indexer must have an appropriate knowledge base and an appropriate set of functions in order to produce quality indexes.
The function requirements are:
Ranging intelligently, given a good knowledge base.
Repetition and novelty discrimination
Word boundary discrimination
Importance detection
Learning ability: particularly, adding to the knowledge base as
the book is indexed
Arranging ability: creating a structure, including first and second
level entries, that reflects the text and is easy to use
The knowledge base requirements are:
An object model capable of holding the knowledge
A populated (by words & other data) general linguistic structure
that relates words to one another, and to sensory knowledge (the
world)
Specific knowledge of the actual subject of the book, including
maps of the intellectual terrain
Picture of the knowledge bases of types of likely users
The overall reason that computers, or machine indexers, cannot produce high-quality book indexes is that no system has yet been devised that allows computers to possess and effectively use knowledge bases that are similar in content and arrangement to human knowledge bases.
The ability of humans to learn about the world and how to use natural languages to represent that world is intimately tied to the human ability to index books. The book indexing process often includes learning about the world and extending the indexer's knowledge of language.
It is possible that at some point in the future a machine indexer with human abilities could be constructed, and a requirements list was generated for this task.
Given the nature of the requirements list above, I do not expect to see machine indexing producing quality indexing any time soon.